Where AI Agents Run: Isolation, Governance, and Cost in the Cloud


The model is not the product. The place where your agent acts—running tools, reading data, calling APIs—is.
If the agent only recommends text, your laptop and a browser tab are enough. Once an agent executes—shell commands, database queries, long-running jobs—that execution needs a runtime you can define, isolate, govern, observe, and pay for on purpose.
This guide is for anyone picking (or reviewing) where that runtime lives. It separates the problem from the solution families so you can reason about new vendors even when names change.
Read this first
- Problem: Tool-using agents need trustworthy execution—not just a smart model.
- Answer: Treat the runtime like production infrastructure: versioned config, isolation, IAM, logs, and cost tags.
- Reality: No single vendor sells “the” agent cloud. You mix compute shape (VM, container, function, microVM) with governance (your cloud account vs a vendor’s).
The problem in one picture
An agent is a loop: plan → act → observe. The act step always touches something real—a process, a network, a secret.
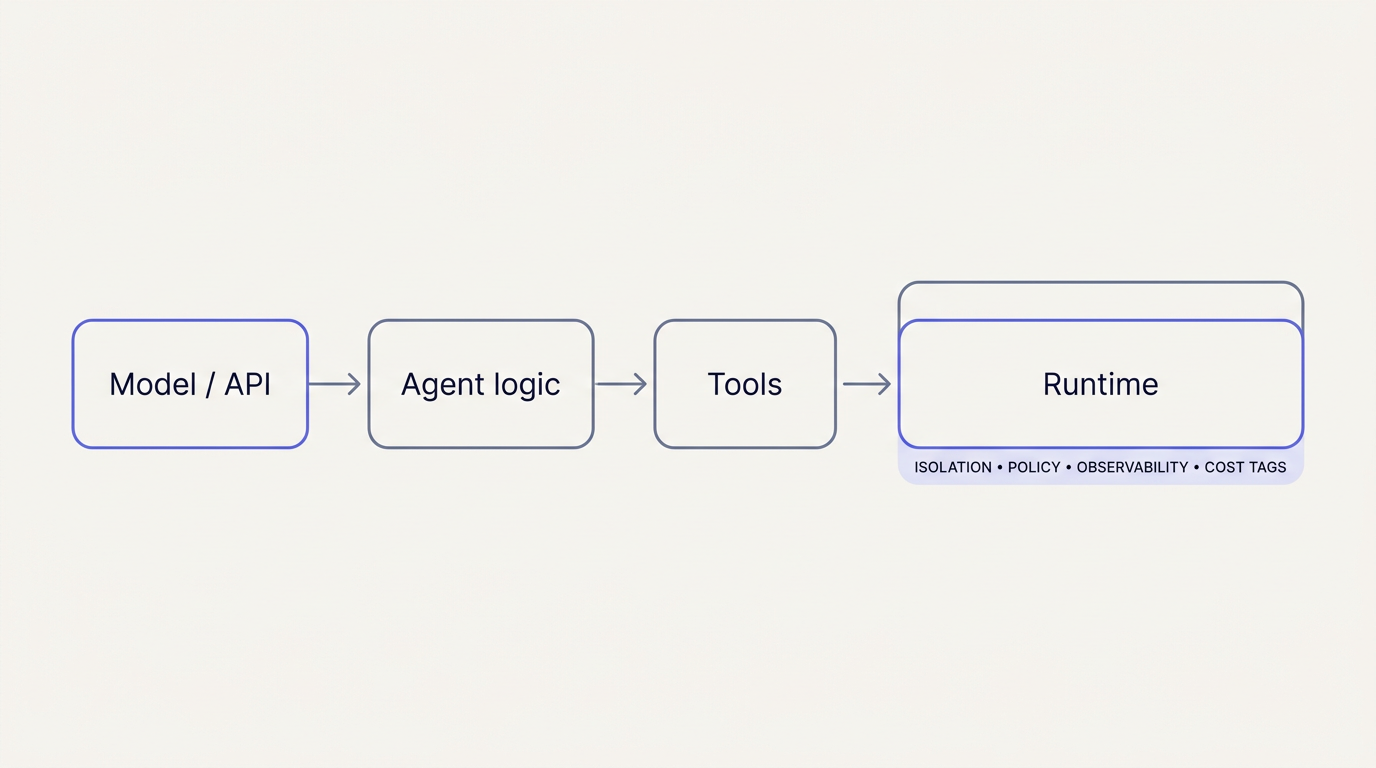
If you skip the runtime discussion, you get shadow IT: agents on laptops with ambient credentials, or “temporary” servers nobody can reproduce. If you design the runtime, security and finance can treat it like any other production system.
Five things every serious setup must get right
Think of these as checklist dimensions—not optional extras for “later.”
| Dimension | Plain English | Why it matters |
|---|---|---|
| 1. Definition | The environment is described in code or manifests (IaC, K8s, task definitions). | You can answer what exactly ran and diff it like software. |
| 2. Isolation | Workloads run in a boundary (VM, microVM, hardened container) with limited blast radius. | Agents are high-privilege; assume bugs and misuse. |
| 3. Control | Who can start a run, what it may call, how long it lives—enforced outside the prompt. | Prompts are not security policy. |
| 4. Observability | Logs, traces, audit trails tied to identity and to a definition version. | Incidents and compliance need evidence, not screenshots. |
| 5. Cost clarity | Tags, budgets, per-team or per-customer attribution for compute and tokens. | Parallel agents spike usage fast. |
Isolation: why “Firecracker” keeps coming up
Containers share the host kernel—great for density, weaker if you need strong separation for untrusted code.
MicroVMs (often built with Firecracker, AWS’s open-source microVM monitor) give a hardware-virtualization boundary in a small footprint. AWS Lambda uses Firecracker-style execution environments; Vercel Sandbox and several AI sandboxes advertise the same class of isolation.
Other patterns you’ll hear about: gVisor (extra layer between container and host—common on Google Cloud), Kata Containers (VM per pod). Same goal—performance vs isolation tradeoffs differ.
A map of solution families (not a vendor shootout)
Before naming products, know which family fits your agent’s shape:
| Family | Typical use | Governance & cost |
|---|---|---|
| Managed dev / Linux workspaces | Repo-centric work, human-like environments | Often bundled with Git + seats; check export of logs |
| VMs & Kubernetes | Full control, custom networking, existing platform team | Best tagging and FinOps integration; you operate more |
| Serverless containers & functions | Event-driven workers, scale-to-zero, no servers to patch | Watch timeouts, concurrency, cold starts in cost models |
| CI/CD runners | Bounded, pipeline-attached steps | Great per-run identity; poor fit for long interactive sessions alone |
| Edge + managed sandboxes | Untrusted code, global routing, API-first | Compose multiple services; read platform limits carefully |
| Purpose-built AI sandboxes & GPU serverless | Tool-using agents, heavy ML steps | Evaluate SOC2, regions, $/minute vs $/seat |
Everything below is an instance of one of these families.
Hyperscalers: VMs, Kubernetes, and the “middle tier”
VMs and Kubernetes (EC2, GCE, Azure VMs, EKS, GKE, AKS)
Best when: You need maximum control, private networking, existing security baselines, or Kubernetes is already standard.
Watch out: You own patching, scaling, and glue—but you also get the richest IAM, network policy, and cost allocation tooling.
Serverless containers and functions
You don’t want to manage EC2? The clouds offer a middle path:
AWS Fargate — run ECS/EKS tasks on AWS-managed capacity: task definitions, IAM, VPC, CloudWatch. Good for batch-shaped or service-shaped agents without running nodes yourself.
Google Cloud Run & Azure Container Apps — HTTP or event-driven containers, scale-to-zero, per-service billing. Good when the agent is a stateless worker behind an API or queue.
AWS Lambda — Short, event-scoped runs with IAM per function and Firecracker-style isolation. Ideal for glue, webhooks, fan-out; pair with Fargate or EKS when you need long runtimes, big images, or shell-heavy toolchains.
Watch out: Timeouts, concurrency caps, and cold starts affect both SLAs and bills.
Managed, repo-backed Linux environments
GitHub Codespaces and similar products: consistent environments from branches, org identity, and predictable minutes-style billing.
Best when: Work looks like software delivery (clone, build, verify).
Watch out: Exotic kernels, hardware, or network needs may push you to general compute.
Long-lived “workstations” (Cloud Workstations, Dev Box, …)
Best when: You standardize human desktops and need IT-style control.
Watch out: Not always tuned for massive parallel ephemeral agent runs without extra automation.
CI/CD as a gate
GitHub Actions, GitLab CI, Cloud Build, CodeBuild, Azure Pipelines: runs are declarative, logged, and tied to pipeline identity.
Best when: Agents run inside release gates or trigger remote sandboxes from a job.
Watch out: Interactive or hours-long sessions usually need another layer.
Edge platforms and managed sandboxes (Vercel, Cloudflare)
These optimize for placement, integration, and disposable execution—not for “I need a pet VM forever.”
Vercel Sandbox
Ephemeral microVMs (Firecracker-class) for untrusted or AI-generated workloads: run, capture output, destroy the boundary.
Best when: You already ship on Vercel and need isolation without folding risk into long-lived functions.
Cloudflare (composition of services)
Workers + Durable Objects — Edge JS/WebAssembly, global, request-level control: routing, auth, rate limits in front of heavier work. Not a full Linux box.
Workers AI + AI Gateway — Model routing, caching, failover, token visibility.
Cloudflare Containers (beta) — More CPU/RAM when Workers aren’t enough; still Workers-orchestrated.
Cloudflare Sandboxes (Sandbox SDK) — Processes, filesystems, tool-using agents on top of Containers.
R2, Queues, Browser Rendering, Vectorize — Artifacts, async, browser automation, retrieval—usually combined with Workers.
Watch out: You may chain several products to match one monolithic cluster—and limits (CPU, wall time, egress) drive cost and architecture.
More options teams actually use
| Category | Examples | Notes |
|---|---|---|
| AI-native sandboxes | E2B, similar APIs | Programmatic sandboxes—check SOC2, data retention, pricing unit. |
| Serverless GPU / Python | Modal, Baseten-style, Replicate-style | Great for ML-heavy steps; weaker if you need a full arbitrary OS. |
| Regional VMs / bare metal | Fly.io, Latitude, Hetzner (where allowed) | Predictable per-VM cost, latency control; you own more ops. |
| PaaS | Railway, Render, Heroku-style | Fast to ship; verify SSO, VPC, log export for production. |
| Cloud dev envs | Gitpod, Codespaces ecosystem | Overlap with managed Linux above; sometimes API-first. |
| Batch on clusters | K8s Jobs, Argo, AWS Batch, Step Functions | Often the cheapest add-on if Kubernetes is already there. |
| Distributed Python | Ray, Anyscale | Scale for training/simulation—not a sandbox by itself. |
Model vendors: intelligence vs execution
OpenAI, Anthropic, Google, etc. sell models. You still decide where tools run—your VPC, cluster, or a vendor sandbox you explicitly choose.
Bundled “agent” products may hide execution. Ask: data residency, audit logs, whether execution can stay in your cloud account, and per-seat vs usage pricing.
API-only models: compare tool-call logging, model version pinning, allowlisted endpoints, and whether token spend and infrastructure spend reconcile in one FinOps view.
Quick-start sandboxes are fine for demos. Production needs the same bar as any regulated workload: SSO, private networking, SLAs, billing tags.
How to choose (durable framework)
Classify the workload — Short tasks vs long sessions? Internal vs customer-facing? Read-mostly vs writes near production?
Codify the environment — If you cannot rebuild from a definition (commit, image digest, manifest), you cannot audit or optimize cost.
Unify telemetry — Same logs / traces / audit standards as the rest of your stack.
Split spend — Separate sandbox vs production accounts or tags; set budgets before scale.
Compare governance and unit economics — IAM, egress, regions, SOC reports, $/vCPU-hour and $/1M tokens—not CPU size alone.
Bottom line
Agents in production are automation. The runtime must be customizable, isolated, controlled, observable, and cost-visible.
Hyperscalers offer primitives and mature FinOps at the cost of assembly. Edge platforms (e.g. Vercel, Cloudflare) offer strong isolation stories and tight product fit at the cost of composition and limit discipline. Model vendors sell intelligence—not your SOC 2 boundary for tool execution.
Shareable takeaways
- The model is not the runtime—tool execution needs the same rigor as any production system.
- Five dimensions: definition-in-code, isolation, control, observability, cost attribution.
- MicroVMs (e.g. Firecracker-class) address strong isolation; Fargate / Cloud Run / Lambda address who manages servers—different questions.
- Pick a family first (VM, serverless container, edge sandbox, CI gate), then shortlist vendors.
- If you can’t prove what ran, what it cost, and who approved it, you’re not ready for unattended agents at scale.
Questions or gaps? The platform landscape changes fast—use the families above as a lens, then validate limits, contracts, and exports with each vendor.